


Η τεχνητή νοημοσύνη εξελίσσεται με ταχύτατους ρυθμούς, και η Ευρώπη βρίσκεται πλέον στην πρώτη γραμμή αυτής της τεχνολογικής επανάστασης. Μια καθοριστική εξέλιξη ήρθε να ενισχύσει την ευρωπαϊκή παρουσία στον χώρο των μεγάλων γλωσσικών μοντέλων μέσω της στενής συνεργασίας δύο πρωτοποριακών πρωτοβουλιών: του HPLT (High Performance Language Technologies) και του OpenEuroLLM.
Η Ιστορική Ανακοίνωση
Οι δύο οργανισμοί ανακοίνωσαν πρόσφατα την κυκλοφορία 38 μονόγλωσσων μοντέλων αναφοράς, καθένα με 2,15 δισεκατομμύρια παραμέτρους. Αυτή η εξέλιξη αποτελεί σημαντικό βήμα προς τη δημιουργία ενός διαφανέστερου και προσβασιμότερου οικοσυστήματος τεχνητής νοημοσύνης στην Ευρώπη. Τα μοντέλα διατίθενται πλήρως δωρεάν για λήψη από τη συλλογή του HPLT στην πλατφόρμα HuggingFace, συμπεριλαμβανομένων και των ενδιάμεσων σημείων ελέγχου ανά 1.000 βήματα εκπαίδευσης.
Τεχνικά Χαρακτηριστικά και Καινοτομίες
Τα μοντέλα εκπαιδεύτηκαν χρησιμοποιώντας το επεξεργασμένο σύνολο δεδομένων HPLT v2, το οποίο καλύπτει ένα εκτενές φάσμα γλωσσών. Συμπεριλαμβάνονται όλες οι επίσημες γλώσσες της Ευρωπαϊκής Ένωσης, καθώς και αρκετές επιπλέον σημαντικές γλώσσες. Κάθε μοντέλο εκπαιδεύτηκε σε 100 δισεκατομμύρια tokens, χρησιμοποιώντας τον tokenizer Gemma-3-27B και ακολουθώντας την αρχιτεκτονική LLaMA με 2,15 δισεκατομμύρια παραμέτρους.
Η εκπαίδευση πραγματοποιήθηκε στον υπερυπολογιστή LUMI, με προϋπολογισμό υπολογιστικής ισχύος περίπου 3.000 ωρών GPU ανά μοντέλο σε επεξεργαστές AMD MI250X. Αυτή η επιλογή αντικατοπτρίζει την ευρωπαϊκή δέσμευση για τεχνολογική αυτάρκεια και ανεξαρτησία στον τομέα της υπολογιστικής ισχύος.
Στόχοι και Οράματα
Κύριος στόχος αυτής της κυκλοφορίας είναι η παροχή ενός διαφανούς και εύκολα αναπαραγώγιμου συνόλου μοντέλων που μπορούν να εξυπηρετήσουν πολλαπλούς σκοπούς. Μεταξύ αυτών περιλαμβάνονται η διαγλωσσική σύγκριση, η αξιολόγηση μονόγλωσσης απόδοσης και η κατανόηση δημοφιλών εργασιών αξιολόγησης για διαφορετικές γλώσσες.
Αυτή η προσέγγιση σηματοδοτεί μια ουσιαστική αλλαγή στον τρόπο ανάπτυξης των μεγάλων γλωσσικών μοντέλων. Αντί για κλειστά συστήματα που ελέγχονται από μεγάλες τεχνολογικές εταιρείες, η ευρωπαϊκή προσέγγιση δίνει έμφαση στη διαφάνεια, την ανοιχτότητα και την επιστημονική αυστηρότητα.
Αποτελέσματα Αξιολόγησης
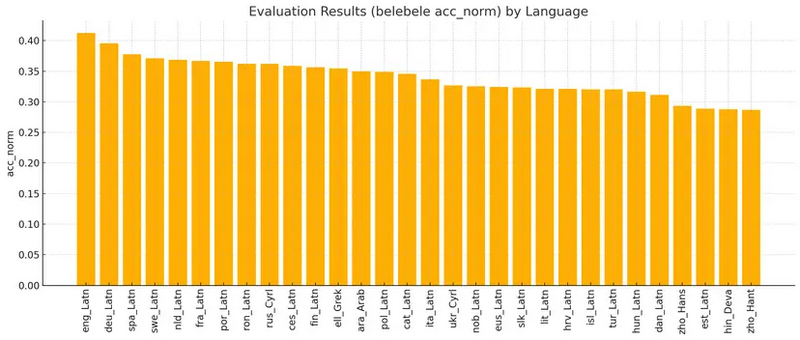
Προκειμένου να καταδειχθούν οι δυνατότητες των μοντέλων, οι ερευνητές παρουσίασαν αποτελέσματα αξιολόγησης για τα μοντέλα αναφοράς των 2,15 δισεκατομμυρίων παραμέτρων. Χρησιμοποιήθηκε το benchmark Belebele, που εστιάζει στην κατανόηση κειμένου με ερωτήσεις πολλαπλών επιλογών, για 30 από τα εκπαιδευμένα μοντέλα. Τα αποτελέσματα αποκαλύπτουν σημαντικές διαφορές στην απόδοση μεταξύ των γλωσσών, γεγονός που υπογραμμίζει την πολυπλοκότητα της πολύγλωσσης τεχνητής νοημοσύνης.
Ιδιαίτερα χρήσιμο είναι το γεγονός ότι τα μοντέλα επιτρέπουν την παρακολούθηση της εξέλιξης της απόδοσης καθ’ όλη τη διάρκεια της εκπαίδευσης στα 100 δισεκατομμύρια tokens. Αυτό παρέχει ανεκτίμητες πληροφορίες για την κατανόηση του τρόπου με τον οποίο τα μοντέλα μαθαίνουν και εξελίσσονται.
Επιπτώσεις για το Μέλλον
Αυτή η πρωτοβουλία έχει ευρύτερες επιπτώσεις για το μέλλον της τεχνητής νοημοσύνης στην Ευρώπη και παγκοσμίως. Δημιουργεί προηγούμενο για τη διαφανή ανάπτυξη μεγάλων γλωσσικών μοντέλων και εφοδιάζει την ερευνητική κοινότητα με εργαλεία για την εις βάθος μελέτη αυτών των συστημάτων.
Επιπλέον, ο πολύγλωσσος χαρακτήρας των μοντέλων ενισχύει την ψηφιακή παρουσία των ευρωπαϊκών γλωσσών και συμβάλλει στη διαφύλαξη της γλωσσικής ποικιλομορφίας στην ψηφιακή εποχή. Αυτό αποκτά ιδιαίτερη σημασία σε μια περίοδο που η τεχνητή νοημοσύνη κυριαρχείται από μοντέλα εστιασμένα κυρίως στην αγγλική γλώσσα.
Προοπτικές και Μελλοντικά Βήματα
Οι υπεύθυνοι των πρωτοβουλιών εκφράζουν την ελπίδα ότι αυτή η συνεισφορά θα οδηγήσει σε διαφανέστερη ανάπτυξη μεγάλων γλωσσικών μοντέλων και προγραμματίζουν να διεξάγουν περαιτέρω πειράματα με επιπλέον σύνολα δεδομένων, benchmarks και επερχόμενες εκδόσεις του συνόλου δεδομένων HPLT.
Αυτή η προσέγγιση αντιπροσωπεύει ένα καθοριστικό βήμα προς μια πιο δημοκρατική και προσβάσιμη τεχνητή νοημοσύνη, όπου η έρευνα και η ανάπτυξη δεν περιορίζονται σε μεγάλες εταιρείες αλλά καθίστανται διαθέσιμες σε ολόκληρη την επιστημονική κοινότητα.
Η κυκλοφορία αυτών των 38 μοντέλων αποτελεί ορόσημο για την ευρωπαϊκή τεχνητή νοημοσύνη και προμηνύει μια νέα εποχή συνεργασίας, διαφάνειας και καινοτομίας στον τομέα των μεγάλων γλωσσικών μοντέλων.
Πηγή άρθρου: https://openeurollm.eu/